![]()

Kof et Julio, voilà un aperçu du TPE, il faut faire la conclusion svp!!!!! ne vous inquiétez pas, avec PowerPoint, c beaucoup + beau!!! (Je vous l'ai envoyé!!) @+
Introduction
La photographie est apparue en 1816, inventée par Niepce puis perfectionnée par Daguerre et Talbot. Depuis lors, son évolution et son importance, culturelle et utilitaire, n’ont cessé de croître. Au point qu’elle est aujourd’hui devenue indispensable à note société : artistique, journalistique (le poids des mots, le choc des photos…), elle est omniprésente dans notre quotidien : qui ici n’a jamais utilisé un appareil photographique ? Une évolution technique de plus en plus poussée en fait un appareil utile à la recherche scientifique de pointe (microphotographie…) ou propice à une utilisation tactique, notamment militaire (photographie satellite).
Même si ces applications nous semblent lointaines, la photographie n’en est pas moins en rapport avec notre vie de tous les jours. Or nous ne connaissons rien ou presque du fonctionnement de cet outil pourtant tellement présent. Nous voulons donc nous intéresser à la photographie et plus particulièrement à cette avancée technologique dont notre époque semble être la charnière : la photographie numérique. En effet, l’apparition de l’appareil numérique représente une vraie révolution pour le grand public et semble avoir un impact géant sur la nature et la fréquence d’utilisation des appareils photographiques et sur le comportement des géants de l’industrie de la photographie.
Dès lors nous pouvons nous demander, pour l’argentique et pour le numérique, comment passe-t-on de la réalité à l’image ?
I - POINTS COMMUNS
Protocole expérimental
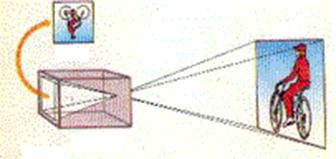
L’appareil photo rudimentaire est constitué de plusieurs éléments, dont l’optique est la base :
- l’objectif (succession de lentilles) qui équivaut à une lentille convergente
- un film qui capte l’image
- un diaphragme
- une chambre noire
Nous avons fabriqué au cours de notre TPE une maquette d’appareil photographique. Nous avons tout simplement découpé une boîte à chaussures en 2, pour permettre à une partie de coulisser, ce qui permettra de régler la netteté. Puis, nous avons insérer un film de papier calque sur un coté de la boîte qui représente la pellicule de l’appareil photo qui capte la lumière. En face, nous avons fait un trou et nous y avons placé la lentille convergente. Enfin, nous avons fabriqué une réglette où étaient découpés des trous de diamètres différents, qui matérialisent les divers diaphragmes, qui permettent de régler la profondeur de champ.


1 - Lentilles convergentes
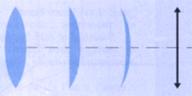

La lentille convergente est un système optique où tous les rayons parallèles de lumières, c’est-à-dire la lumière provenant de l’infini, convergent vers le foyer image F’. Cette lentille est fine sur les bords et large au centre. Chaque lentille a une distance focale qui lui est propre : elle correspond à la distance entre le foyer image F’ et le centre optique O de la lentille. Sur un appareil photo, on peut très légèrement avancer ou reculer l’objectif pour permettre au foyer image F’ de coïncider avec la pellicule, et ainsi d’avoir une photo nette.
![]()
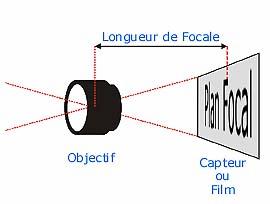 Comme
le montre cette illustration, plus cette distance est élevée, plus le champ de
vision sera restreint vu que l'angle obtenu sur l'objectif va se réduire.
Comme
le montre cette illustration, plus cette distance est élevée, plus le champ de
vision sera restreint vu que l'angle obtenu sur l'objectif va se réduire.
2 – Diaphragmes et profondeur de champs
*Un diaphragme est l’ouverture circulaire par laquelle rentre la lumière lors du déclenchement de la photo. Cette ouverture est variable et peut être réglée par l’utilisateur pour limiter l’intensité de lumière arrivant dans l’appareil ; elle est caractérisée par le nombre "f", qui est le rapport du diamètre utile d'un objectif à la distance focale de celui-ci. Sur nos appareil photo, on a f qui prend les valeurs : 1 - 1.4 - 2 - 2.8 - 4 - 5.6 - 8 - 11 - 16 - 22 - 32 - 45... "f" sert donc à désigner la valeur d'ouverture du diaphragme et il est bon à savoir que les valeurs sont le double de la suivante ou la moitié de la précédente : f:2 laisse passer deux fois plus de lumière que f:2,8 et, f.32 deux fois moins que f.22. Pour sa part f.1 correspond à la totalité de la lumière admise.
Les différents diaphragmes permettent ainsi de ne pas surexposer la pellicule : si par exemple nous sommes en bord de mer avec beaucoup de soleil, et si nous utilisons f :1, c’est-à-dire nous laissons passer la totalité de la lumière, alors la pellicule aura reçu trop de lumière et donc sera surexposée, c’est à dire blanche à certains endroits. Par contre, si nous nous trouvons en milieu obscur, toute la lumière sera nécessaire pour que la photo soit visible.

*Le diaphragme a aussi une conséquence sur la profondeur de champ : c’est la distance maximale selon laquelle l'objet peut ainsi se déplacer tout en gardant une image nette.
Une grande ouverture du diaphragme donnera peu de profondeur de champ : le premier plan est net mais le fond de l'image est flou... (voir photo 1) Une petite ouverture du diaphragme donnera une grande profondeur de champ : l'ensemble de l'image est nette ... (voir photo 2)


Photo 1 Photo 2
*Ensuite, nous avons l’obturateur, qui s'ouvre lorsqu'on prend la photographie. L'ouverture, dont la durée est réglable, est provoquée par le déclencheur. L'Obturateur est un système mécanique (parfois électronique), qui permet de contrôler la durée du temps d'exposition c'est-à-dire la durée pendant laquelle la lumière va pouvoir pénétrer jusqu'au capteur. La vitesse d’obturation est exprimée en secondes et prend des valeurs comme : 2 - 1 - 1/2 - 1/4 - 1/8 - 1/15 - 1/30 - 1/60 - 1/125 - 1/250 - 1/500 - 1/1000 - 1/2000 - 1/4000 et plus .... La durée d'exposition est la résultante de la durée d'ouverture de l'obturateur et du diamètre du diaphragme. On l’appelle aussi « temps de pose ». Si l'objet est en mouvement, il faut un temps de pose court, sinon son déplacement pendant la durée de l'exposition sera perceptible et l'image sera floue. Mais cet effet peut être recherché…
Photo de la cathédrale , ou d’autres
Schéma récapitulatif :

II – Pellicule argentique : le développement photographique
La photographie dite argentique tient son nom du procédé de développement qui la caractérise : en effet, ce dernier utilise une propriété des ions Ag+ : les ions argent. Nous allons donc nous intéresser au détail de ce procédé qui, même s’il peut sembler archaïque à l’ère du numérique n’en reste pas moins irremplaçable au moins en ce qui concerne la photo d’art et professionnelle.
Le concept général du développement photographique peut être résumé assez simplement : une pellicule sensible à la lumière est exposée pendant un court instant, certaines zones sont imprégnées à des degrés différents, d’autres non et de cette différence résulte un négatif emprunt de l’image.
La base, le support de cette technique, c’est évidemment la pellicule photographique. Il s’agit en fait d’un film recouvert de micro – cristaux d’halogénures d’argent (taille de l’ordre du mm) qui ont une propriété bienvenue : la photosensibilité. Les pellicules couleur contiennent en plus des substances organiques capables de générer les trois couleurs du trichrome (la trichromie correspond à la superposition 3 couleurs primaires : jaune, cyan et magenta, à partir desquelles on peut recréer n’importe quelle couleur) lors du développement.
Remarque : il existe des films dits plus ou moins « rapides ». Cela signifie en fait qu’ils auront besoin d’une exposition plus ou moins longue à la lumière pour êtres impressionnés. Ainsi lorsque l’on veut photographier quelque chose de mobile ou de rapide (voiture, photographie sportive, missiles…) il est nécessaire de se munir de films plus rapides qui sont cependant désavantagés e cas de forte luminosité par exemple…
Après avoir fait votre choix, vous faites donc votre photo, et là arrive le procédé technique, le développement :
Que s’est-il passé lorsque vous avez pris votre photo ? (nous supposerons une pellicule de bromure d’argent AgBr sans chlorure d’argent ClBr) Hé bien clic-clac, ouistiti et tout le bazar : la lumière arrive sur la pellicule sous la forme d’un photon qui va sauvagement arracher un électron périphérique à un ion bromure : Br- + photon -> Br° + e- : un radical brome et un électron sont produits. Le radical Brome ira directement voir un ami dans la même situation : 2 Br° -> Br2, c’est une oxydation photochimique. L’électron ne va pas se balader longtemps, en effet, il sera vite capté par un ion Ag+ car Ag+ + e- -> Ag (oui cela fait beaucoup d’Ag surtout s’il s’agit d’un pote âgé qui prend une photo de son potager…). Plus la quantité de lumière reçue est importante, plus la quantité d’atomes d’argent formés dans les cristaux sera importante : la pellicule « mémorise » ainsi la quantité de lumière reçue lors de l’exposition en chaque point : c’est la photographie noir et blanc.
Les composés organiques utilisés lors de la photographie couleur ont un fonctionnement trop complexe pour pouvoir être utilisés dans un TPE de terminale sans sacrifier au moins un élève par surcharge de travail, nous avons donc abandonné l’idée de faire le détail de ce fonctionnement, merci de votre clémence…
À ce degré du développement, les atomes d’argent se sont regroupés à l’intérieur des micro – cristaux, ces agrégats sont cependant invisibles, ils constituent ce qu’on appelle techniquement l’image latente.
On passe donc le film impressionné dans un révélateur pendant un temps donné (le révélateur est un bain de composés organiques) qui va réduire les ions Ag+ proches des agrégats d’atomes d’argent déjà présents (au cas où vous n’auriez pas suivi ;). Du métal argent se dépose donc sur les parties impressionnées du film.
Dès lors, les parties impressionnées sont assombries, les autres restent claires, d’où le terme « négatif » !
Dans le cas d’une pellicule couleur, les composés organiques au fonctionnement complexe font naître simultanément les différentes couleurs sur le négatif.
Une fois l’image argentique (le négatif) apparue sur le film, il est nécessaire de passer le film dans un bain fixateur afin d’éviter qu’il noircisse encore à la lumière. Un bain dans une solution de thiosulfate de sodium dissout le bromure d’argent encore présent dans la gélatine du film, ce qui rend ce dernier stable à la lumière, autrement dit fixé.
On possède dès lors un négatif stable qui, après un lavage à l’eau distillée et un séchage, va être agrandi et projeté sur un papier photographique qui a en fait les mêmes propriétés que la pellicule et qui subira les mêmes traitements que cette dernière. Ce papier sera donc le négatif du négatif, c’est à dire la reconstitution de l’image elle-même.
Photo du labo de Foch
III - Appareil numérique
a) Capteurs numériques

Tout comme dans un appareil photo argentique, le capteur est situé dans l’axe optique pour qu’il puisse recevoir de la lumière. Il est composé de nombreux photosites sensibles à la lumière : ces cellules photosensibles vont émettre un courant proportionnel à la quantité de lumière reçue. Le courant ainsi produit reconstitue l’image. Cependant, ces photodiodes ne sont pas sensibles à la couleur, elle reconstituent l’image en noir et blanc : cela s’explique par le fait que le pixel est binaire (0 si il n’y a aps de lumière, 1 si la lumière est transmise). C’est pourquoi on doit placer un filtre RVB (rouge, vert, bleu) – aussi appelé filtre de Bayer - devant le capteur. Il rend les photosites sensibles à d’autres nuances : rouge, vert, bleu.
Il y avait 380.000 photodiodes au début, on en est maintenant à 8.000.000 grâce à l’évolution. Mais cela a commencé à devenir une limite lorsque les capteurs sont arrivés au chiffre de 3.34 millions. En effet jusque là, on ajoutait un million de photosites par an à ce qui existait déjà, en conservant la même surface. On générait donc des photodiodes de plus en plus petites mais la surface où elles étaient apposées ne variait pas. Par conséquent, des problèmes apparaissaient : une perte de sensibilité (la surface de chaque photosite diminuant) donc de luminosité, donc créant du "bruit" vidéo (notamment dans les parties sombres de la photo). Le bruit vidéo est une restitution incorrecte des couleurs d'une image (par exemple des points gris clair sur une partie de l'image qui est censée être uniformément blanche). Dans certains cas, on peut éliminer ce bruit grâce à des logiciels de retouche.
 Les
capteurs les plus courants sont du types CCD (Charge Coupled Device) : carrés ou
rectangles microscopiques photosensibles fixés sur une plaque de silicone. On
considère que 4 photosites sont nécessaires pour former un pixel (contraction de
Picture ELement), et non pas un photosite par pixel, comme tout le monde le
croit. Plus le nombre de photosites est élevé, plus la qualité finale de
l’image, ainsi que sa résolution seront bonnes et que sa taille sera élevée.
Ex : aujourd’hui, les appareils reflexes numériques bon marché affichent 8
millions de pixels, certains allant même jusqu’à 16 millions. Il y a peu de
temps, les appareils photos numériques ne dépassaient pas le million de pixels.
Les
capteurs les plus courants sont du types CCD (Charge Coupled Device) : carrés ou
rectangles microscopiques photosensibles fixés sur une plaque de silicone. On
considère que 4 photosites sont nécessaires pour former un pixel (contraction de
Picture ELement), et non pas un photosite par pixel, comme tout le monde le
croit. Plus le nombre de photosites est élevé, plus la qualité finale de
l’image, ainsi que sa résolution seront bonnes et que sa taille sera élevée.
Ex : aujourd’hui, les appareils reflexes numériques bon marché affichent 8
millions de pixels, certains allant même jusqu’à 16 millions. Il y a peu de
temps, les appareils photos numériques ne dépassaient pas le million de pixels.
Remarque : On trouve aussi d’autres technologies de capteurs sur le marché : les CMOS, super CCD, le X3,… cela varie en fonction du constructeur. Les capteurs dits CMOS sont moins chers à la construction mais sont moins précis c’est à dire nettement plus sensibles au « bruit ».
Expérience
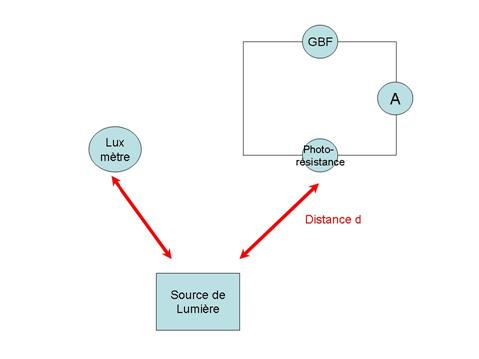
Protocole expérimental :
Le materiel utilisé lors de cette experience est :
_une photoresistance
_un Générateur Basse Fréquence
_un ampèremètre
_un luxmètre
_une source de lumière
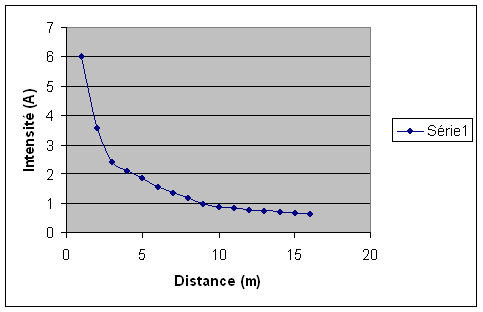
Le but de cette experience est de reproduire simplement le mécanisme d’acquisition par capteurs d’un appareil numérique. En effet, la photoresistance agit ici comme un capteur de lumière, dès lors, il suffit de comparer les variations de l’intensité (ampèremetre) dans le circuit de la photoresistance avec celles de la lumière (luxmètre) qui varient en éloignant la source lumineuse.
Schéma du montage :
On peut compiler les resultats sous la forme d’un tableau et de courbes.
|
distance (m) |
Intensité (A) |
luminosité (lux) |
|
0,1 |
6 |
2000 |
|
0,2 |
3,57 |
1000 |
|
0,3 |
2,4 |
800 |
|
0,4 |
2,1 |
700 |
|
0,5 |
1,875 |
500 |
|
0,6 |
1,57 |
400 |
|
0,7 |
1,36 |
350 |
|
0,8 |
1,2 |
300 |
|
0,9 |
1 |
270 |
|
1 |
0,9 |
250 |
|
1,1 |
0,86 |
220 |
|
1,2 |
0,79 |
200 |
|
1,3 |
0,75 |
190 |
|
1,4 |
0,71 |
170 |
|
1,5 |
0,68 |
160 |
|
1,6 |
0,66 |
150 |

Conclusion :
La résistance créée par la photoresistance augmente donc au fur et à mesure que la luminosité décroit : plus il y a de lumière, moins il y a de résistance, plus l’Intensité transmise au circuit est importante.
On peut mettre ce système de fonctionnement en parallèle avec celui d’un capteur d’appareil photographique numérique qui envoie un signal à partir d’une certaine intensité lumineuse qui sera ensuite stockée sur la memory card
2°) Stockage sur la memory card
Exemple: la compression d’image en jpeg
Cela se fait en 3 étapes successives :
- l’image normale prise est tout d’abord transformée par DCT.
DCT est le sigle pour Discret Cosin Transform. Ce principe a été trouvé par le professeur Rao de l’université du Texas en 1974. C’est une opération très complexe (trop pour notre niveau) qui transforme une donnée x captée par les photosites en une donnée y, grâce à une opération complexe faisant intervenir des cosinus, le nombre pi,…
- les données ainsi trouvées sont regroupées dans une matrice, qui va être remplacée par une matrice de quantification : on transmet des valeurs approximatives de la matrice précédente en se donnant un pas de quantification. Prenons un exemple : pour un pas de 4 : les valeurs 0,1,2 et 3 seront codées par 0, les valeurs 4,5,6 et 7 seront codées par 1, etc… Cette opération est destructrice car elle entraîne une déformation des informations.
- Enfin, la dernière opération est le codage statique. Il fonctionne grâce aux statistiques : les valeurs les plus récurrentes sont codées dans des petits nombres de bits. Cette opération aussi appelée « code de Huffman » est conservatrice car aucune donnée n’est perdue.
Voilà, l’image est compressée. Il va ensuite y avoir un certain nombre de bit par pixel et cette structure de chaque pixel codera pour une certaine couleur et pour un certain endroit sur l’image. Un octet représente 8 bits. Nous allons le représenter sous forme de 2 paquets de 4 bits. Avec 4 bits, nous pouvons coder 2x2x2x2=16 nombres différents. Donc les octets sont codés en base 16, l’hexadécimal, et sont donc représentés par 2 symboles.
Quand la photo sera décompressée, pour être vu sur un écran d’ordinateur par exemple, l’opération est l’inverse de celle de la compression.

IV – Résolution et profondeur de couleur (photo numérique)
1°) La profondeur de couleurs
La qualité d'une photographie numérique est notamment définie par le nombre maximal de couleurs que peut prendre chaque pixel. La profondeur de couleur est le nombre de bits associés à chaque couleur primaire d'un pixel. Cette valeur reflète le nombre de couleurs ou de niveaux de gris d'une image.
Cette profondeur de couleur est calculée avec la formule suivante :
2^(nombre de bits)
|
Profondeur de Bit |
Nombre de couleurs affichables par pixel |
|
1 |
2 |
|
4 |
16 |
|
8 |
256 |
|
16 |
65536 |
|
24 |
16,7 millions |
Nous avons vu précédemment que 8 bits forment un octet. Il y a donc 28 possibilités soit 256 possibilités de couleur pour chaque octet. La quantité de chacune de ces couleurs varie entre 0 (pas de cette couleur) à 255 (toute la quantité possible de cette couleur)
Prenons un exemple : pour la couleur « bleu » :

Ce bleu est composé de 22 de rouge, 53 de vert et 200 de bleu. Cette association fait que l’ordinateur va afficher une couleur bleue.
Maintenant, voici 4 images identiques, mais codées en profondeur de couleur différente :


1 bit 4 bits


8 bits 24 bits
Pour l’image codée en 1 bit, la possibilité du pixel est : soit noir, soit blanc, donc l’image est en noir et blanc.
Pour l’image codée en 4 bits, il n’y a que 16 possibilités de couleur pour chaque pixel, donc, sur une photo, le codage en 4 bits est très insuffisant.
C’est pour cela que les photos sont codées en 24 bits (16.7 Millions de couleurs), et non pas 8 bits, car là encore, il n’y a pas assez de possibilité de couleur…
2°) La résolution
La qualité d’une photo numérique est aussi et surtout définie par sa résolution. La résolution, c’est le nombre de pixels (Picture ELement) en largeur et en longueur. Plus il y a de pixels, plus la résolution est grande, plus la qualité est bonne, plus la photo est « lourde » (elle occupe beaucoup de place sur la carte mémoire et sur le pc). Par exemple, l’Institut TNO TPD a crée la plus grande image numérique : elle est composée de 2,5 milliards de pixels et elle occupe une surface de 6,67 * 2,67 mètres et pèse 7 Go sur le disque dur !!!!!
Sur la photo suivante, nous pouvons observer chaque pixel, matérialisé par un carré de la grille. Chaque pixel a donc sa propre couleur, avec une certaine quantité de rouge, de bleu et de vert (RVB). Cette image pèse 4 Ko et mesure 150 * 83 soit 12450 pixels.

Conclusion:
????????????????